 以下のページに記載されたJavaScriptを理解したいので、すべての行について理解できるまで解読してみるぞ。
以下のページに記載されたJavaScriptを理解したいので、すべての行について理解できるまで解読してみるぞ。
- ウェブページから NG ワードを消すグリースモンキー
http://d.hatena.ne.jp/amachang/20100123/1264261110
[合いの手] なぜ理解したいんだい?
[話者] そのページのJavaScriptには私が学びたい機能が使われているんだ。
「ページがJavaScriptで更新されたとき、更新部分にGreasemonkeyを適用する」という方法についてなのだけど。いまの私には理解できないので、読みながら学ぼうと‥‥。
http://d.hatena.ne.jp/amachang/20100123/1264261110の機能を取り入れたスクリプトを作成し、http://d.hatena.ne.jp/itouhiro/20110107で公開しました。
[合いの手] ふむふむ。
[話者] まず、このJavaScriptは全体を以下の2行で囲っている。
(function() { ..(内容).. })();
これは、以下の知識があれば理解できる。
(1)
JavaScriptでは関数の定義に、C言語やJavaでおなじみの
function myFunc() { var t = new Date(); var s = "現在時刻は" + t.toString() + "です"; document.write(s); }
という形式
(関数宣言とか function文とか呼ぶらしい)
以外にも、
var myFunc = function() { var t = new Date(); var s = "現在時刻は" + t.toString() + "です"; document.write(s); };
という形式
(関数リテラル とか 関数式(function式) と呼ぶようだ)n
も使える。
前者の定義でも、後者でも、
myFunc();
で実行できる。
(2)
で、その関数名さえ付けずに実行だけしたい場合は、
さっきの後者の形式のfunction() { }をカッコで囲んで、
末尾に(関数実行のための)()をつける。
(function() { var t = new Date(); var s = "現在時刻は" + t.toString() + "です"; document.write(s); })();
関数名を付けていないので、無名関数っていうんだ。
このカッコの付け方は、functionについてのリンク先でまとまって書かれているよ。
[合いの手] ちょっと待った。なんで無名関数で囲むことが必要なの? 最初の行と最後の行を省いた以下でも動作するでしょ。
var t = new Date(); var s = "現在時刻は" + t.toString() + "です"; document.write(s);
[話者] それだと変数 t とか s がグローバル変数になってしまうんだよ。
JavaScriptで変数を局所化する(変数のスコープを狭くする)には、関数の中に置くしかないんだ。
[合いの手] なるほど。グローバル変数はよくないって言われるからね。それを避けるためか。
[話者] まあ実際には現在のFirefoxのGreasemonkeyに限れば囲まなくても問題はないが、囲っておいたほうが安全らしい。
[合いの手] ふーん。ところで上のコードはどうすれば動かせる?
[話者] たとえばこんなHTMLファイルをブラウザで読み込めばいい。
<html> <head> <script type="text/javascript"> (function() { var t = new Date(); var s = "現在時刻は" + t.toString() + "です"; document.write(s); })(); </script> </head> <body> <p>こんにちは。</p> </body> </html>
[合いの手] ふむふむ‥‥。おっ、GoogleChrome6では、結果がこうなった。<body>タグの直後に開始するタグより、前に実行されるんだな。
現在時刻はFri Sep 17 2010 10:32:41 GMT+0900 (Japan Standard Time)です こんにちは。
[話者] または
ブラウザ上でJavaScript実行できるページ http://jsdo.it で入力してみるとか。
[合いの手] ほほう。
[話者] 話を戻して、次はここを理解しよう。
var ngwords = <![CDATA[ RT @ QT @ (via @ ]]>.toString().split(/\n/).map(function(w) w.replace(/(^\s+)|(\s+$)/, '')).filter(function(w) w.length);
まず、<![CDATA[ 〜 ]]>だが、これで囲まれた部分は Character Data(文字データ)として扱われる。
どういうことかというと、この中に<i>わーお</i>とか&と書いても、ブラウザが「わーお」を斜体に変換して表示したり「&」と変換して表示したりしない。「<i>わーお</i>」とか「&」という文字のままにする。
[合いの手] プログラム言語でいえば、PHPのシングルクォートは、以下のように、エスケープシーケンスの「\n」を解釈しない、というのと同じだね。
echo 'ab\ncd'; # → ab\ncd echo "ab\ncd"; # → ab(改行)cd
[話者] で、その結果を.toString()でひとつなぎの文字列にして、その結果を.split(/\n/)で1行ごとに要素に分けた配列にする。
[合いの手] JavaScriptはこんなふうに次々メソッドをつなげていけるんだねー。
[話者] この方法はメソッドチェーンと呼ばれている。
で、その配列に対して、.map(function(w) w.replace(/(^\s+)|(\s+$)/, ''))を実行している。
mapメソッドは置いておいて、まず中身の
function(w) w.replace(/(^\s+)|(\s+$)/, '')を先に解読するぞ。
これは、Firefox3以降で使えるJavaScript1.8の書き方だ。以下で説明されている。
http://d.hatena.ne.jp/amachang/20070613/1181712586
JavaScript1.6までの書き方でやると、以下のように書いたのと同じ。
function(w){ return w.replace(/(^\s+)|(\s+$)/, ''); }
この無名関数は、
パラメータ文字列 w に対して、replaceメソッドで文字列先頭と末尾の空白を削除している。PHPでいえば trim関数だな。
[合いの手] ちょいとWait。 無名関数とは (function XX{})() のことだってさっき言ったよね?
[話者] いや、それは無名関数の「実行」。無名関数っていうのは単に関数に名前をつけないってことだよ。つまり、
(1) var array2 = array1.map(function(w){ return w.replace(/(^\s+)|(\s+$)/, '');});
というソース片は、以下のように書いても動作は同じだ。
(2) var myStringReplaceFunc = function(w){ return w.replace(/(^\s+)|(\s+$)/, ''); } var array2 = array1.map(myStringReplaceFunc);
(2)では一度しか使わない関数に myStringReplaceFunc なんて名前をつけてるけど、そんな名前いらないじゃないか、ということで(1)のソースのように書くのが無名関数。無名関数のメリットも参考になる。
[合いの手] ‥‥
[話者] それで、mapメソッドは配列の各要素に対して、関数を実行するんだ。
で、各要素が処理された、新しい配列を次のメソッドに渡します。
[合いの手] ようするに、ここは、配列の各要素をtrimしただけなんだね。
[話者] 次はこれ。.filter(function(w) w.length)
filterメソッドは関数でテストして合格した要素だけを含む、新しい配列を返します。
つまり、String.lengthメソッドでサイズが0の空文字列か調べて、空文字列を配列からはじき出す。
JavaScriptでは 数字の 0 はfalseだから、文字列のサイズで0を返すとテストで不合格になるんだね。
[合いの手] なるほど。ようするに、この例でいうと以下の配列を宣言したのと同じだよね。結果として。
var ngwords = ['RT @', 'QT @', '(via @'];
[話者] 結果としてはそうだね。
次はclean(document.body)。この clean関数はソースのこの後で宣言されている。それをここで実行しているんだね。
document.bodyというのは、<body>タグのDOMノードを返すよ。
[合いの手] DOMノード?
[話者] 表示されているHTML要素をJavaScriptで操作することができるんだが、そのとき「DOMを扱うことで」操作するんだ。
たとえば以下のHTMLで document.getElementById がDOMなんだ。
<html> <head> <script type="text/javascript"> setTimeout(function(){ document.getElementById('msg1').firstChild.nodeValue = "(2) よく来たな!歓迎するぜ!";}, 1000); </script> </head> <body> <p id="msg1">(1) こんにちは。</p> </body> </html>
詳しくはDocument Object Model、言語中立なインターフェース群を見るとかGoogle検索してみてくれ。
[合いの手] おっ! 1秒後に表示メッセージが変わるんだ。
[話者] だから、document.body のノードを受け取ると、<body>タグと、その下の<p>タグと、その下の「(1) こんにちは。」文字列データを操作することができる。操作するっていうのは、中身を書き換えるとかだな。
[合いの手] ふむふむ。
[話者] 次は、
document.addEventListener('DOMNodeInserted', function(e) { clean(e.target) }, false);だ。
addEventListenerを使うと、特定の「イベント」が起きたときに、指定された関数を実行するんだ。
この例だと、DOMNodeInserted というイベントが起きたとき、function(e){...}という無名関数を実行するんだな。
[合いの手] イベントってなんなの? RPGでいう花嫁選択イベントとか、あるいは現実でいうフジロックみたいな。
[話者] ここでいうイベントっていうのは、ブラウザの中で起きることだ。以下で決まっているよ。
http://www.w3.org/TR/DOM-Level-2-Events/events.html#Events-eventgroupings
そのページによると、具体的には以下のがあるようだ。
DOMFocusIn DOMFocusOut DOMActivate click mousedown mouseup mouseover mousemove mouseout DOMSubtreeModified DOMNodeInserted DOMNodeRemoved DOMNodeInsertedIntoDocument DOMAttrModified DOMCharacterDataModified load unload abort error select change submit reset focus blur resize scroll
JavaScript書くときに、HTMLタグに onclick="..." とか onsubmit="..." って書くだろ? あれから on を外したのが、ここに集まってると考えていいかな。
[合いの手] ああ、あれがイベントなのか。
でも DOMNodeInserted っていうのは見たことないね。
[話者] それではそのページの説明を見てみようか。
DOMNodeInserted
Fired when a node has been added as a child of another node. This event is dispatched after the insertion has taken place. The target of this event is the node being inserted.
Bubbles: Yes
Cancelable: No
Context Info: relatedNode holds the parent node
Fired when .. を訳すと、
このイベントは、別のノードの子として、ノードが追加されたとき発砲されます。
このイベントが発行されるのは、ノードの挿入が起こった「後」です。
target は、挿入されたノードです。
[合いの手] targetっていうのは何だろう?
[話者] それはこのe.targetのtargetだよ。
document.addEventListener('DOMNodeInserted', function(e) { clean(e.target) }, false);
Webページで、DOMNodeInsertedイベントが発行されたら、addEventListenerの第2パラメータの関数を実行します。その関数は Event型のパラメータをとることに決まっています。
で、そのEvent型変数 e がもつ targetというプロパティを、clean関数に渡します。
[合いの手] e.targetを受け取った clean関数は、「挿入されたノード」にアクセスすることができるんだね。
[話者] さて、次の
document.addEventListener('DOMCharacterDataModified', function(e) { clean(e.target) }, false);
はイベントの種類が違うだけだな。
この DOMCharacterDataModified は「ノードの中の文字データが変更されて、しかもノード自身は追加も削除もされてないとき発行されます。また、PI 要素が変更されたときも発行されます。target は文字データのノードです」
PI要素っていうのは ProcessingInstruction の略で、今回はあまり気にしなくてよいみたいだ。
さて次は
document.addEventListener('DOMAttrModified', function(e) { if (e.target.tagName.match(/^(input|option)$/i)) clean(e.target) }, false);
この DOMAttrModified は「ノードの属性 (Attr) が変更されたとき発行されます。target は、Attrの変更されたノードです」
具体的には、フォームのテキストボックス、つまり <input type="text"> や <textarea></textarea> の中の文字列が変更されたときなどに、発行されるみたいだな。
http://help.dottoro.com/ljdchxcl.php に例がある。
[合いの手] このスクリプトで扱うイベントはこれで全部だね。
[話者] 次はescapeXPath関数を先に見るよ。
function escapeXPath(text) {
textという変数をパラメータで受け取って、
それが以下の正規表現にマッチするか調べている。
var matches = text.match(/[^"]+|"/g);
"ではない文字列が1つ以上続くとマッチする。または"にもマッチする。
gフラグがついているので、グローバルなマッチ。つまり文字列に一回ヒットしたら終わりではなく、マッチするかを文字列の最後まで走査する。そしてマッチのすべてを含む配列を返す。マッチがひとつもないとnullを返す。
参照:JavaScriptのString.match
[合いの手] それってテキスト全部にマッチしているんじゃ?
[話者] そうだよ。
変数matchesは配列だ。その配列要素は、ダブルクォート文字か、ダブルクォート以外の文字列になる。
function esc(t) { return t == '"' ? ('\'' + t + '\'') : ('"' + t + '"'); }
この関数は、
受け取ったパラメータが文字"だった場合は「'〜'」のようにシングルクォーテーションで囲む。
受け取ったパラメータが文字"以外だった場合は「"〜"」のようにダブルクォーテーションで囲む。
それだけ。
[合いの手] 関数の中で関数を宣言できるのね。
[話者] さっきいったvar f = function(){};の形式考えれば分かるように、関数も変数もおんなじ扱いだからな。関数の中で関数を宣言する利点は、この関数がグローバル関数じゃなくて、ローカル関数になる点がよいんだ。
さて次は
if (matches) { ...(略)... } else { return '""'; } }
このif (matches) {文は、変数matchesが、マッチしたのがなくてnullだったときは、elseのほうが実行される。その場合""という文字列を返してこの関数終了。
if (matches.length == 1) { return esc(matches[0]); }
matches.lengthが1というのは"が出現しない文字列、または"1文字だけの場合だ。まあほとんどは"が出現しない文字列だろうな。
この場合、matches配列の唯一の要素をクォーテーションつけてエスケープして返して、この関数終わり。
else { var results = []; for (var i = 0; i < matches.length; i ++) { results.push(esc(matches[i])); } return 'concat(' + results.join(', ') + ')'; }
matches.lengthが2かそれ以上の場合は、配列matchesのそれぞれの要素をシングルクォートかダブルクォートかで囲んで、
たとえば
Dawkins's concept of a meme could be described as an "evolving idea".
という文章は変数matchesに入るとき
- Dawkins's concept of a meme could be described as an
- "
- evolving idea
- "
- .
という5つの要素に分解されている。
そのあとこの箇所で変数resultsに入ると、以下のように内容が変化する。
- "Dawkins's concept of a meme could be described as an"
- '"'
- "evolving idea"
- '"'
- "."
そしてreturnするとき
concat("Dawkins's concept of a meme could be described as an", '"', "evolving idea", '"', ".")という文字列で返す。これでこの関数の処理はすべて見た。
次に clean関数を見よう。
function clean(node) { switch (node.nodeType) { ...(略)... } }
Node型の変数nodeをパラメータとして受け取ったよ。
この変数のプロパティ nodeTypeは数値を持ってて、数値の意味は
Node.nodeType に説明がある。
このスクリプトでは nodeType が 1 つまり ELEMENT_NODEの場合と、3 つまり TEXT_NODEの場合に処理をしているね。
function clean(node) { switch (node.nodeType) { case 1: ...(略)... case 3: ...(略)... } }
[合いの手] ELEMENT_NODE?
[話者] Elementノードっていうのは、HTMLタグのノードだよ。Textノードっていうのは、文字列テキストのノードだ。
たとえば、こんなHTMLがあったとする。
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd"> <html xmlns="http://www.w3.org/1999/xhtml" xml:lang="ja" lang="ja"> <head> <meta http-equiv="Content-Type" content="text/html; charset=UTF-8" /> <title>aaa</title> </head> <body><p id="msg1">ジャイアン<select id="sel1"><option selected="selected">ドラ</option><option>のび太</option></select><textarea rows="2" cols="8">スネ夫</textarea><input type="text" value="しずちゃん" /></p></body> </html>
HTMLの<body>タグの中を見ると、以下のような構造になっているね。
<p id="msg1"> ジャイアン <select id="sel1"> <option selected="selected"> ドラ </option> <option> のび太 </option> </select> <textarea rows="2" cols="8"> スネ夫 </textarea> <input type="text" value="しずちゃん" /> </p>
これをFirefoxのDOMインスペクターというのでDOMとしてみると‥
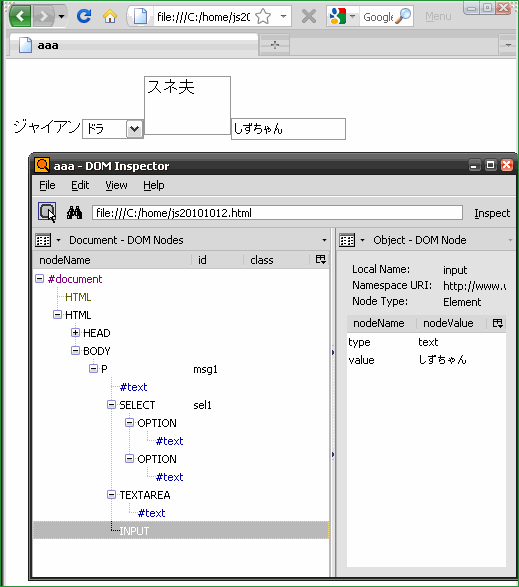
こんなDOMツリー構造になっているんだ。
「#text」というのがTEXTノード、
「P」「SELECT」「INPUT」‥などが ELEMENTノードだ。
[合いの手] なるほど、なるほど。
[話者] で、nodeType が 1 つまり ELEMENT_NODEの場合を、まず見てみよう。
[合いの手] 図を見ると、<input>タグのvalueの値は、テキストノードじゃなくて、Elementノードに含まれてるよね。
<input type="text" value="しずちゃん" />
[話者] そうだな。
if (node.tagName.match(/^(input|option)$/i)) node.value = '';
この処理は、「nodeのタグ名が input か option のときは、nodeのvalueを空文字列にしろ」ということだね。
node.tagNameでHTMLタグ名を取り出している。
ちょっと試してみよう。以下のHTMLをブラウザに表示させると‥
<html> <head> <meta http-equiv="Content-Type" content="text/html; charset=UTF-8" /> </head> <body> <p id="text1">ドラ <input id="text2" value="のび太" /> </p> <script type="text/javascript"> n = document.getElementById('text2'); document.write('tagName=' + n.tagName); </script> </body> </html>
GoogleChrome6では tagName=INPUT と表示される。
[合いの手] ふむふむ。
[話者]
tagName.matchの部分で正規表現でマッチするかを確認している。
正規表現のiオプションを指定してるので、タグ名が大文字でも小文字でもマッチする、つまりinputでもINPUTでもInpuTでもマッチする。
で、正規表現の先頭に ^ 記号があって終端に $ があるので、タグ名が superinput とか inputsuper ならマッチしなくて、input の文字列の前や後ろに何もつかない場合だけマッチする。
[合いの手] そんなタグ名、HTMLにはないよー。
[話者] いや、さっきのHTMLで<inputを<superinputに変えると、JavaScriptでtagNameを取得したとき tagName=SUPERINPUT と表示される。
[合いの手] ムリヤリだな。
[話者] 続きだが、node.value = '';の部分で、<input>タグ等のvalueが空文字列になる。さっきの図だと、<input>タグのvalueが 'しずちゃん' だったが、これが空になるということだな。ちょっと試してみよう。
<html> <head> <meta http-equiv="Content-Type" content="text/html; charset=UTF-8" /> </head> <body> <p id="text1">ドラ <input id="text2" value="のび太" /> </p> <script type="text/javascript"> var deltext = function(){ n = document.getElementById('text2'); if(n.tagName.match(/^(input|option)$/i)){ n.value = ''; } }; setTimeout(deltext, 1000); </script> </body> </html>
このHTMLをブラウザで表示すると、表示して1秒後に「のび太」の文字列が消える。
[合いの手] 確かに消える。
[話者] つぎは以下の部分を解読しよう。
else if (ngwords && ngwords.length) { ‥‥ }
elseとあるから、inputタグとoptionタグ以外のタグだった場合、この中を実行するわけだな。
if (ngwordsというのは、変数ngwordsは配列なのかをチェックしているようだ。
JavaScriptの配列は、要素を含むものも、含まない空配列でも、
評価すると必ずtrueを返すのだ。
[合いの手] if(カラの配列)の判定がtrueになるのか‥これは他の言語と違うね。
[話者] 空文字列とか、数値の0ならfalse判定なのだが、配列はオブジェクトだからな‥
たとえば、以下のHTMLをブラウザに表示すると
<html> <head> <meta http-equiv="Content-Type" content="text/html; charset=UTF-8" /> </head> <body> <p id="text1">ドラ <input id="text2" value="のび太" /> </p> <script type="text/javascript"> var str = ''; document.write('void str = ' + Boolean(str) + '<br />'); var num = 0; document.write('number 0 = ' + Boolean(num) + '<br />'); var obj = null; document.write('Object null = ' + Boolean(obj) + '<br />'); var num2 = NaN; document.write('Number NaN = ' + Boolean(NaN) + '<br />'); var un = undefined; document.write('undefined = ' + Boolean(un) + '<br />'); var arr = []; document.write('void array = ' + Boolean(arr) + '<br />'); </script> </body> </html>
void str = false number 0 = false Object null = false Number NaN = false undefined = false void array = true
という結果になるぞ。
続いて、ngwords.lengthの判定のほうで、空配列かどうかをチェックしている。空配列なら 0 を返すので、false判定になるからな。
次を見ていこう。
var xpath =
'.//text()[' +
ngwords.map(function(w) 'contains(.,' + escapeXPath(w) + ')').join(' or ') +
'] | (.//input | .//option)[' +
ngwords.map(function(w) 'contains(@value,' + escapeXPath(w) + ')').join(' or ') +
']';
ngwords.map(function(w) 'contains(.,' + escapeXPath(w) + ')')の部分で、配列 ngwordsの各要素にescapeXPath関数を適用して、文字列を追加している。
[合いの手] ん?具体的には‥
[話者] 具体的には、ここで
配列 ngwordsの中身 (要素が3つ)
RT @ QT @ (via @
これが以下のように変化する。
要素が3つの配列
contains(.,'RT @') contains(.,'QT @') contains(.,'(via @')
そして、.join(' or ')があるから、配列の3つの要素が一つの文字列に変化する。
contains(.,'RT @') or contains(.,'QT @') or contains(.,'(via @')
そのあとの+ '] | (.//input | .//option)[' + ngwords.map(function(w) 'contains(@value,' + escapeXPath(w) + ')').join(' or ')も同じような処理だ。
この処理を通すと、文字列変数xpathは
.//text()[contains(.,'RT @') or contains(.,'QT @') or contains(.,'(via @')] | (.//input | .//option)[contains(@value,'RT @') or contains(@value,'QT @') or contains(@value,'(via @')]
という値を持つことになる。
[合いの手] 処理はそれほどでもないけど、作られた文字列が複雑になってきたぞ‥
[話者] これは XPath という文法になっているんだ。
続く:
- [JavaScript] 「ウェブページから NG ワードを消すGM」を解読(2)
http://d.hatena.ne.jp/itouhiro/20101218

Head First JavaScript ―頭とからだで覚えるJavaScriptの基本
- 作者: MichaelMorrison
- 出版社/メーカー: オライリージャパン
- 発売日: 2008-08-14
- メディア: 大型本
おすすめ度の平均:
 びっくりするほどおもしろいPC書籍
びっくりするほどおもしろいPC書籍