[話者] Xpath学習の、次のターゲットはこれ。
http://userscripts.org/scripts/review/1295
ソースは短い。
// ==UserScript== // @name Linkify // @namespace http://youngpup.net/userscripts // @description Looks for things in the page that look like URLs but aren't hyperlinked, and converts them to clickable links. // @include * // ==/UserScript== (function () { const urlRegex = /\b(https?:\/\/[^\s+\"\<\>]+)/ig; // tags we will scan looking for un-hyperlinked urls var allowedParents = [ "abbr", "acronym", "address", "applet", "b", "bdo", "big", "blockquote", "body", "caption", "center", "cite", "code", "dd", "del", "div", "dfn", "dt", "em", "fieldset", "font", "form", "h1", "h2", "h3", "h4", "h5", "h6", "i", "iframe", "ins", "kdb", "li", "object", "pre", "p", "q", "samp", "small", "span", "strike", "s", "strong", "sub", "sup", "td", "th", "tt", "u", "var" ]; var xpath = "//text()[(parent::" + allowedParents.join(" or parent::") + ") and " + "contains(translate(., 'HTTP', 'http'), 'http')]"; var candidates = document.evaluate(xpath, document, null, XPathResult.UNORDERED_NODE_SNAPSHOT_TYPE, null); var t0 = new Date().getTime(); for (var cand = null, i = 0; (cand = candidates.snapshotItem(i)); i++) { if (urlRegex.test(cand.nodeValue)) { var span = document.createElement("span"); var source = cand.nodeValue; cand.parentNode.replaceChild(span, cand); urlRegex.lastIndex = 0; for (var match = null, lastLastIndex = 0; (match = urlRegex.exec(source)); ) { span.appendChild(document.createTextNode(source.substring(lastLastIndex, match.index))); var a = document.createElement("a"); a.setAttribute("href", match[0]); a.appendChild(document.createTextNode(match[0])); span.appendChild(a); lastLastIndex = urlRegex.lastIndex; } span.appendChild(document.createTextNode(source.substring(lastLastIndex))); span.normalize(); } } var t1 = new Date().getTime(); //alert((t1 - t0) / 1000); })();
[合いの手] このGreasemonkeyスクリプトはどんな効果があるの?
[話者] テキストで http://ai11.net/2010/fbicon/ のように、http〜で始まっているのにリンクが張ってない場合、ときどきあるよな。
このスクリプトを入れていると、そういう文字列をリンクつきに自動で変換してくれる。
[合いの手] へえ。
[話者] それではソースを見ていこう。
const urlRegex と var allowedParents
は単なる定数と配列変数の宣言だな。
ちなみに 配列 allowedParentsのタグ一覧に a が入っていないのがポイントだ。「aタグがない→リンクされていない」ということなので、リンクを新たに付け加える必要が出てくる。
var xpath = "//text()[(parent::" + allowedParents.join(" or parent::") + ") and " + "contains(translate(., 'HTTP', 'http'), 'http')]";
これも文字列変数の宣言だが、変数の中身がどうなるか、実際に見てみよう。
以下のHTMLをブラウザで表示させると、変数の中身を表示する。
https://sites.google.com/site/itouhiro/2010/xpathtest05.html
<?xml version="1.0" encoding="UTF-8"?><!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd"> <html xmlns="http://www.w3.org/1999/xhtml" xml:lang="ja" lang="ja"> <head><meta http-equiv="Content-Type" content="text/html; charset=UTF-8" /><title>Xpath test</title></head> <body><pre> <script type="text/javascript">//<![CDATA[ (function() { var allowedParents = [ "abbr", "acronym", "address", "applet", "b", "bdo", "big", "blockquote", "body", "caption", "center", "cite", "code", "dd", "del", "div", "dfn", "dt", "em", "fieldset", "font", "form", "h1", "h2", "h3", "h4", "h5", "h6", "i", "iframe", "ins", "kdb", "li", "object", "pre", "p", "q", "samp", "small", "span", "strike", "s", "strong", "sub", "sup", "td", "th", "tt", "u", "var" ]; var x1 = allowedParents.join(" or parent::"); document.write("var x1 = \"" + x1 + "\"\n"); var xpath = "//text()[(parent::" + allowedParents.join(" or parent::") + ") and " + "contains(translate(., 'HTTP', 'http'), 'http')]"; document.write("var xpath = \"" + xpath + "\"\n"); })(); //]]> </script></pre></body> </html>
結果として、変数 xpath の内容は、こう宣言した場合と同じだな。
var xpath = "//text()[(parent::abbr or parent::acronym or parent::address or parent::applet or parent::b or parent::bdo or parent::big or parent::blockquote or parent::body or parent::caption or parent::center or parent::cite or parent::code or parent::dd or parent::del or parent::div or parent::dfn or parent::dt or parent::em or parent::fieldset or parent::font or parent::form or parent::h1 or parent::h2 or parent::h3 or parent::h4 or parent::h5 or parent::h6 or parent::i or parent::iframe or parent::ins or parent::kdb or parent::li or parent::object or parent::pre or parent::p or parent::q or parent::samp or parent::small or parent::span or parent::strike or parent::s or parent::strong or parent::sub or parent::sup or parent::td or parent::th or parent::tt or parent::u or parent::var) and contains(translate(., 'HTTP', 'http'), 'http')]"
[合いの手] 長いのね。
このXpath式で「parent::」は何だろう?
[話者] Xpathの規格書
http://www.w3.org/TR/1999/REC-xpath-19991116/
に書いてあるけど、実際に見たほうが早いね。
このサンプルHTMLで試すと、
https://sites.google.com/site/itouhiro/2010/xpathtest01.html
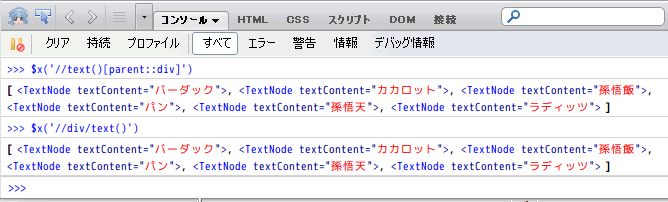
このXpath式と
//div/text()
こっちのXpath式は
//text()[parent::div]
同じことがわかる。
[合いの手] 上の //div/text() は、まず<div>タグをHTMLからすべて取り出して、そのすべてのdivタグに対して、直下の階層にあるテキストノードを取り出しているね。
下の //text()[parent::div] はまずテキストノードを取り出すんだけど「一つ上の階層が<div>タグのもの」という条件をつけている。
結果としては同じになるわけだ。
[話者] そう。
別のサンプルHTMLで試すと、
https://sites.google.com/site/itouhiro/2010/xpathtest02.html

この2つのXpath式を足したものが
//p/text() //option/text()
このXpath式と同値だ。
//text()[parent::p or parent::option]
[合いの手] ふむふむ。
「parent:: or ..」って書くことで、Xpath式をまとめて書ける、まとめて取り出せるという利点があるのか。
さっきの変数の中身の終わりのほうを見ると、わからないのがあるぞ。
var xpath = "//text()[(parent::abbr or parent::acronym ... or parent::var) and contains(translate(., 'HTTP', 'http'), 'http')]"
contains って何だっけ?
[話者] 指定した文字を含んでいるテキストノードだけ取り出すよ。
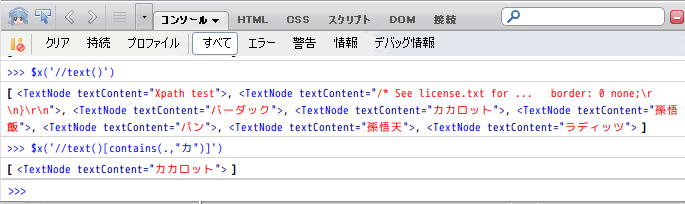
[合いの手] おー、Xpathだけで文字検索できるのか。
translate って何だろう。
[話者] これは文字の置き換えをするんだ。
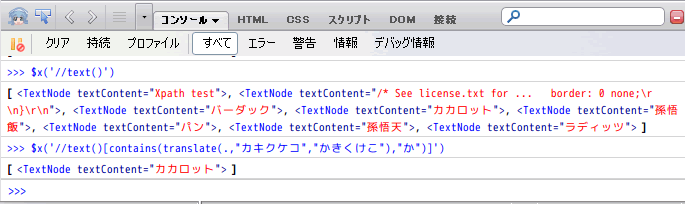
この例では
まず、このXpath式で
translate(.,"カキクケコ","かきくけこ")
コンテキストノード(処理中のノード)の「カ」の文字を「か」に置換する。同様に「キ」→「き」、「ク」→「く」、「ケ」→「け」、「コ」→「こ」、と置換する。その上で、
contains(translateの結果, "か")
を実行する。
translateの結果、文字列「カカロット」は「かかロット」になっているので、containsで「か」を検索したときに引っかかるわけだな。
[合いの手] はあ。
つまり、
contains(translate(., 'HTTP', 'http'), 'http')]
は、文字列「HTTP」を「http」に置換したうえで、httpという文字列を含んでいるテキストノードを取り出す、というわけか。
[話者] これで変数xpathの中身がわかった。
- 「「配列 allowedParents にリストアップされたHTMLタグ」の階層1段階下にある」テキストノード
- http または HTTP を文字列として含む
という条件を満たしたテキストノードを取り出すためのXpath式だ。
次のソースは、ここだ。
var candidates = document.evaluate(xpath, document, null, XPathResult.UNORDERED_NODE_SNAPSHOT_TYPE, null);
変数 candidates にはXpath式を評価した結果が入る。
[合いの手] evaluateの引数がちょっと難しくみえるぞ。
[話者] 以下に説明があるよ。
evaluateの引数は
- Xpath式
ここでは変数xpath - コンテクストノード
ここではHTML文書全体 (documentというのはルートノードのことのはず) - 名前空間解決関数
nullでいいようだ。 - 結果の型
XPathResult.UNORDERED_NODE_SNAPSHOT_TYPE というのは数字の 6 を指定しても同じだ。「返される XPathResult オブジェクトはマッチしたノードの静的なノード集合」と書いてある。 - 結果
nullの場合新規XpathResultオブジェクトを生成。
「スナップショットは文書が変異しても変更されず、イテレータと違って無効になることはありませんが、スナップショットは現在の文書に対応しません。」と書いてある。なるほどー。
上に書いてある「静的なノード集合」というのは、つまりスナップショット作成後にDOMツリーを変更しても、スナップショットの中身は動的に変更されませんよ、いったん作ったスナップショットはもう変更されませんつまり静的です、ということ。
[合いの手] ようするに、変数 candidates にはスナップショットが入るというわけだね。
[話者] そう。
その変数から中身を取り出すためには、
JavaScript で snapshotItem() プロパティを使うよ。
for (var cand = null, i = 0; (cand = candidates.snapshotItem(i)); i++) {
forループでは snapshotLength プロパティを使うのが通常だけど、ここでは使ってないね。
「snapshotItem(i)のiに存在しない数値を指定すると null を返す」という仕様を利用している。その仕様はどこに書いてあるか不明だけど、 https://sites.google.com/site/itouhiro/2010/xpathtest03.html で試すと確かに null を返す。
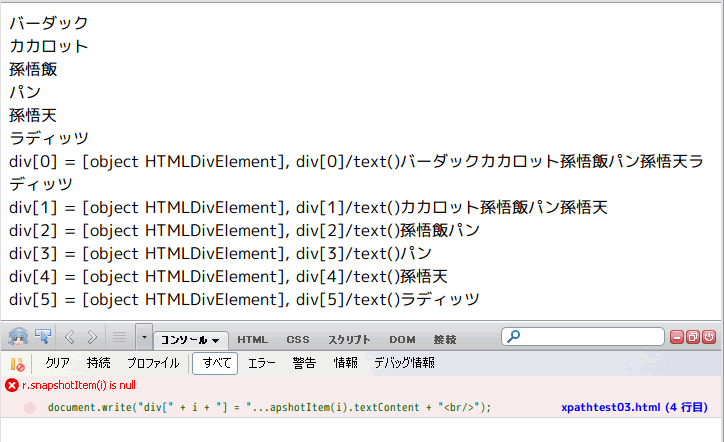
[合いの手] 次のコードはここだ。
if (urlRegex.test(cand.nodeValue)) {
[話者] これは正規表現だね。
仕様を見ながら確認しよう。
https://developer.mozilla.org/ja/Core_JavaScript_1.5_Reference/Global_Objects/RegExp
変数 urlRegex はソースの上のほうでこう宣言されている。
const urlRegex = /\b(https?:\/\/[^\s+\"\<\>]+)/ig;
この正規表現を読み解くと、
- \b はboundaryつまり単語の切れ目がここにあるという条件。
- その次の ( から ) まででマッチした文字列を、この正規表現式は返す。正規表現をJavaScriptでexec()使えば、返した文字列を取得できる。
https://developer.mozilla.org/ja/JavaScript/Reference/Global_Objects/RegExp/exec - https?: は「http:」または「https:」にマッチ。後述のiフラグがあるので、「HTTP:」とか「HttP:」など大文字小文字がちがってもマッチするよ。
- \/\/ は単に「//」にマッチ。
- [^ から ] までは、その中に入ってる文字クラスにマッチする「以外のもの」にマッチする。
- \s+\"\>\< というのはスペース(空白、タブ、改行)と「+」と「"」と「<」と「>」にマッチ。
この正規表現が具体的にどうマッチするのか、以下のサンプルで確認できるぞ。動作はHTMLソースを見てね。
https://sites.google.com/site/itouhiro/2010/xpathtest04.html
ところで、JavaScriptで正規表現の g フラグつけると、なぜだかマッチするべき要素をマッチしないことが起きる。サンプルでもgフラグは外しているぞ。
(追記: 正規表現とループでハマりどころ - prog*sig にgフラグの挙動の説明がある)
[合いの手] なるほど確かに、「http」から始まって、「+」や「"」の直前までマッチしてるね。「+」とかの文字にはマッチしないんだね。
[話者] exec()ならマッチした文字列を取り出せるけど、text()の場合は正規表現にマッチしたかしてないか、という結果だけわかる。
https://developer.mozilla.org/ja/JavaScript/Reference/Global_Objects/RegExp/test
cand.nodeValue というのは、
cand = candidates.snapshotItem(i)
というソースで cand にテキストノードのスナップショットが入っているから、
そのテキストを nodeValueで取り出してるようだね。
[合いの手] snapshotItemに格納されてる文字列を取り出すのは、
さっきの
- https://developer.mozilla.org/ja/Introduction_to_using_XPath_in_JavaScript
- https://sites.google.com/site/itouhiro/2010/xpathtest04.html
では、textContentプロパティで取り出してるよ。nodeValueでも取り出せるのか?
[話者]
snapshotItemがテキストノードの場合は、nodeValueでもtextContentでも同じ結果だ。
https://sites.google.com/site/itouhiro/2010/xpathtest05.html
snapshotItemが要素ノードの場合は、nodeValueではテキストを取り出せない。textContentなら、要素ノードの階層下にあるテキストがすべて結合されたものを取得できる。
https://sites.google.com/site/itouhiro/2010/xpathtest07.html
[合いの手] snapshotItemがテキストノードの場合、textContentで そのノードの階層下にあるテキストがなぜ結合されないの?
[話者] テキストノードというのは、それより下の階層がないと決まってるから。結合しようにも結合できないんだよ。 http://d.hatena.ne.jp/itouhiro/20101223 の図などで確認してね。
次のソースは
var span = document.createElement("span"); var source = cand.nodeValue; cand.parentNode.replaceChild(span, cand);
createElementは
https://developer.mozilla.org/ja/DOM/document.createElement
に説明がある。
ようするにJavaScriptを使ってHTMLソースを書き換えるとき、新規挿入する<span>タグを挿入する前に、createElementで生成して、それを挿入するということだな。
そして、replaceChildでテキストノード cand をspan要素に置き換える。
https://developer.mozilla.org/ja/DOM/element.replaceChild
これで、span要素がHTMLソースの中というか、DOMツリーに出現することになったぞ。
[合いの手] テキストノード cand は消えてしまったのか?
[話者] ノードとしては消えてしまった。しかし中身のテキストに関しては、変数sourceに残っているぞ。
urlRegex.lastIndex = 0; for (var match = null, lastLastIndex = 0; (match = urlRegex.exec(source)); ) { span.appendChild(document.createTextNode(source.substring(lastLastIndex, match.index))); var a = document.createElement("a"); a.setAttribute("href", match[0]); a.appendChild(document.createTextNode(match[0])); span.appendChild(a); lastLastIndex = urlRegex.lastIndex; }
lastIndexは
https://developer.mozilla.org/ja/JavaScript/Reference/Global_Objects/RegExp/lastIndex
によると「正規表現が、グローバルサーチを示す"g" を使用した場合にのみ、セットされます。」だそうだ。
ようするに文字列の途中まででマッチした場合、マッチするかを確認するのはその次の文字から、という処理だ。
appendChildは
https://developer.mozilla.org/ja/DOM/Node.appendChild
createTextNodeは
https://developer.mozilla.org/en/DOM/document.createTextNode
さっき置き換えて出現したspan要素はまだカラだったけど、span要素の下にテキストノードを追加したぞ。
そのテキストノードの中身の文字列は、
source.substring(lastLastIndex, match.index) だから、
https://developer.mozilla.org/ja/Core_JavaScript_1.5_Reference/Global_Objects/String/substring
lastLastIndexは正規表現が検索する最初の文字
match.indexというのは、exec
https://developer.mozilla.org/ja/JavaScript/Reference/Global_Objects/RegExp/exec
の結果で「文字列のマッチの 0 ベースの位置」とある。
match[0]というのは「最後にマッチした文字」。
setAttributeで
https://developer.mozilla.org/ja/DOM/element.setAttribute
<a>タグの属性にリンク先を追加して、spanタグの下に<a>タグを追加。
[合いの手] ここらへん解説が適当になってる。
[話者] 実はここらへんは知りたい場所じゃないので。
あとは normalize
https://developer.mozilla.org/ja/DOM/element.normalize
を使うと、空のテキストノードが取り除かれて、隣接したテキストノードは結合される。
これでソース解析おわり。
[合いの手] なんとか流れはつかめた。

- 作者: ShelleyPowers
- 出版社/メーカー: オライリージャパン
- 発売日: 2009-11-30
- メディア: 大型本