[ http://d.hatena.ne.jp/itouhiro/20101030 の続きです]
[話者] XPathの勉強しようと、はてなブックマークでXPathタグのついた記事
http://b.hatena.ne.jp/t/xpath
を探してみた。
http://d.hatena.ne.jp/mollifier/20100607/p1 さんの記事を読むと、
[合いの手] しかしFireBugの配布サイト https://addons.mozilla.org/ja/firefox/addon/1843/ 、画像がなんか・・いやな画像だよね。
[話者] そこで、「FireBugのアイコンを置き換えようじゃなイカ」 http://ai11.net/2010/fbicon/ というサービスを作ったよ。

アイコン画像を別のに置き換えできる。これでFireBugを気軽に使えるぞ。
[合いの手] でもほかの人が作ってくれたFireBugの使い方説明サイトをみるときは、やっぱりその画像を見るはめになるという‥‥。
[話者] ‥‥。
それはともかくFireBugの使い方を学ぼう。
コンソールで $x('//div[@class="center"]') のように入力することで、XPathを試すことができる。

このコンソールに現れた結果をマウスオーバーすると、その要素を特定するXPath式が表示されるし、画面上にその要素を表示してればハイライトされる。右クリックでXPath文字列を取得できる。クリックするとFireBugの[HTML]タブに飛び、該当するHTMLソースを見れる。

‥‥なるほど、少しずつ分かってきた。
$x('/html/body/div/div')と入力して、
[div#header, div#div_articles, div#footer]
と表示されたら、次に
$x('/html/body/div/div[2]')と入力すると、
[div#div_articles]
と表示される。
FireBugだと配列が 1 から始まるので、[2] と指定すると配列の2つめが取得できるのか。
そして
$x('//div')というふうに頭に // とスラッシュ2つ重ねたら、ドキュメント全体から検索することになって、階層と関係なく <div>タグを取得できる。
[合いの手] ふーん。
[話者] さて前回のソース解読で、
変数xpathの中身は
.//text()[contains(.,'RT @') or contains(.,'QT @') or contains(.,'(via @')] | (.//input | .//option)[contains(@value,'RT @') or contains(@value,'QT @') or contains(@value,'(via @')]
という値になった。
そして残りのソースコードはこの2行だけだった。
r = document.evaluate(xpath, node, null, 7, null);
for (var i = 0; i < r.snapshotLength; i ++) r.snapshotItem(i).textContent = '';
ソースコードから見ていこう。
document.evaluate() に関しては
「XPath ってなんなの!?」 http://d.hatena.ne.jp/amachang/20071112/1194856493
に使い方が書いてあるが、ようするに Xpath式を解釈する関数だ。
で、この関数が返す値は、ただの配列とかじゃない。
https://developer.mozilla.org/ja/Introduction_to_using_XPath_in_JavaScript
によると「XPathResult オブジェクト」だ。
[合いの手] ふむふむ。
[話者] そのXPathResultオブジェクトから値を取り出すやり方は、ふつうの配列とはちがう。
具体的には、
これだけ分かれば、この2行はXPath式にヒットした要素すべてに対して、 .textContent = '' つまり文字列データをカラにしているだけと理解できる。
textContentプロパティの使い方も見ておこう。
ここは参考になるかな。
サンプルHTMLで動作をみよう。
https://sites.google.com/site/itouhiro/2010/firebug13.html
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="ja" lang="ja"> <head> <meta http-equiv="Content-Type" content="text/html; charset=UTF-8" /> <title>Xpath test</title> </head> <body><p id="msg1">ジャイアン<select id="sel1"><option selected="selected">ドラ</option><option>のび太</option></select><textarea rows="2" cols="8">スネ夫</textarea><input type="text" value="しずちゃん" /></p><pre> <script type="text/javascript">//<![CDATA[ (function() { var x1 = '//p'; var r = document.evaluate(x1, document, null, 7, null); document.write("XpathObject('" + x1 + "') length = " + r.snapshotLength + "<br/>"); for (var i=0; i<r.snapshotLength; i++){ document.write("XpathObject('" + x1 + "') item[" + i + "] = " + r.snapshotItem(i) + "<br/>"); document.write("XpathObject('" + x1 + "') item[" + i + "].textContent = " + r.snapshotItem(i).textContent + "<br/>"); } })(); //]]> </script> </pre></body> </html>
このHTMLを表示すると

こんな感じ。
[合いの手] textContentで取得した値が「ジャイアンドラのび太スネ夫」となってる。
下のノードのテキストもいっぺんに取得できてしまうんだね。
[話者] 上のサンプルHTMLを少し変更して、
setTimeout(function(){ r.snapshotItem(0).textContent = "こんにちは";}, 1000);
を追加したら‥‥
https://sites.google.com/site/itouhiro/2010/firebug15.html

[合いの手] ジャイアンだけじゃなくてのび太まで「こんにちは」に消されたー。
つまり下のノードもまとめて操作できてしまうわけだね。
[話者] そうみたいだな。
ソースコードの読解をつづけるよ。
次の問題は、変数'xpath'に入っているXPath式だ。
 ・・これは長いな。
・・これは長いな。
.//text()[contains(.,'RT @') or contains(.,'QT @') or contains(.,'(via @')] | (.//input | .//option)[contains(@value,'RT @') or contains(@value,'QT @') or contains(@value,'(via @')]
 短く区切ればいい。
短く区切ればいい。
http://www.infoteria.com/jp/contents/xml-data/REC-xpath-19991116-jpn.htm
に XPath 1.0のリファレンスがあるので見比べてみよう。
[合いの手] うーん。いきなり .//text() っていうのがリファレンスに見当たらない。
[話者] こういうときのFireBug。
FireBugコンソールで、.//text() と入力すると‥‥。

[合いの手] おおっテキストコンテントがいろいろ取得できた。スラッシュn は‥なんだろう。
[話者] これは改行。DOMでは改行も「文字」として認識してしまうんだ。
- <head> の前の3つの改行がひとまとめで取得できている。
- <head> 直後の改行ひとつ。
- <meta> の行の改行ひとつ。
- <title> の中身のテキスト。
- <title> の行の改行ひとつ。
- <p> 直後のテキスト。
- <option> の中身のテキスト。
- <option> の中身のテキスト。
- <textarea> の中身のテキスト。
という結果だね。
[合いの手] で .//text() は何なの?
[話者] text() は
text() はコンテキストノードのすべての子テキストノードを選択する。
とリファレンスに書いてあるな。
.//は
.//para はコンテキストノードの para という名前の子孫エレメントを選択する。
とある。
[合いの手] コンテキストノードって何なの?
[話者] http://www.atmarkit.co.jp/aig/01xml/contextnode.html を見ると「基準点となるノード」のことらしい。
具体的には FireBugで調べてみる。
リファレンスによると
. はコンテキストノードを選択する。
なのだから、FireBugで $x('.') と入力すると‥‥

[合いの手] おお、[Document foobar.html] のことだったのか。
[話者] ちなみに、// と .// の違いは
http://d.hatena.ne.jp/blooo/20091012/1255323254
に書いてある。
document.evaluateを使うときにはXPathの指定で先頭にドットを付けるようにする。
つまり"//div"ではなくて".//div"とする。
そうしないと「継ぎ足されたページのみ適用」はできない。
このソースコードは、JavaScriptで文字列を読み込んできてページのHTMLを継ぎ足したものにも、適用する仕様だから、 .// じゃなきゃだめなのだな。
[合いの手] そうか。
で、この .//text() のあとに
[contains(.,'RT @') or contains(.,'QT @') or contains(.,'(via @')]
というのがあるね。やれやれ。
[話者] ここはしつこく追っていくだろ。
角カッコ [ ] で囲んだ部分は「述語(Predicates)」と呼ぶらしい。google:xpath 述語
「ノードテスト text() で指定した集合」を絞り込む(フィルタリング)する役目があるという。
containsは関数で、
関数: boolean contains(string, string)
contains 関数は、1番目の引数に指定した文字列が2番目の引数に指定した文字列を含んでいる場合に真を返し、それ以外は偽を返す。
とある。
実際にやってみようぜ。

なるほど確かに使えてる。
[合いの手] contains(.,'QT @')に2つ引数があるのはわかるけど、ひとつめの引数が . だよね。これはなんだろう?
[話者] 説明が見つからない‥。
http://msdn.microsoft.com/ja-jp/library/ms256133(VS.80).aspx を見ると
contains() 関数を変更して、最初の引数でドット セレクタ (".") を使用してみましょう。
contains(.,'Banana')
この場合は、文字列 "AppleBananaOrange" が検索される
と書いてある。
textContentプロパティで取り出したときの文字列、つまり上の例だと「ジャイアンドラのび太スネ夫」、がドットセレクタ?に入るのかな?
あっ、リファレンスにも次のように書いてある。
string 関数は、以下のようにオブジェクトを文字列に変換する。
ノード集合内のノードのうち、ドキュメント順で最初のノードの文字列値を返して、ノード集合を文字列に変換する。 ノード集合が空の場合には、空の文字列を返す。
string関数以外にも、containsなどの文字列関数にもこれは当てはまるということだろうな。
つまり、. はカレントノード(コンテキストノード)のこと。
そして文字列関数の引数でノードを与えると、文字列に自動で変換して処理してくれる。
でもFireBugの結果で、「ドラ」「のび太」が別々の結果になっているところをみると、. の変換が「ジャイアンドラのび太スネ夫」一つにまとまるわけではなくて、個々に文字列化されてフィルタされるようだ。
[合いの手] ソースコードここまではわかったよ。次は
| (.//input | .//option)[contains(@value,'RT @') or contains(@value,'QT @') or contains(@value,'(via @')]
だけど。
[話者] .//input と .//option はtext()がテキストノードにマッチするのとは違って、単に <input> と <option> のHTMLタグにマッチする表現だな。
実際に見てみよう。このHTMLをサンプルにする。
https://sites.google.com/site/itouhiro/2010/firebug22.html
<?xml version="1.0" encoding="UTF-8"?><!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd"> <html xmlns="http://www.w3.org/1999/xhtml" xml:lang="ja" lang="ja"> <head><meta http-equiv="Content-Type" content="text/html; charset=UTF-8" /><title>Xpath test</title></head> <body><p id="msg1">ジャイアン<select id="sel1"><option selected="selected" value="ドラえもん">ドラ</option><option>のび太</option></select><textarea rows="2" cols="8">スネ夫</textarea><input type="text" value="しずちゃん" /><label><input type="checkbox" name="n1" value="出木杉" />出木杉</label><label><input type="checkbox" name="n1" value="ドラミ" />ドラミ</label><input type="hidden" id="hdn1" value="怪物くん" /><input type="submit" value="21エモン" /></p></body> </html>
構造としては、こうなってる。
<p id="msg1">
ジャイアン
<select id="sel1">
<option selected="selected" value="ドラえもん">
ドラ
</option>
<option>
のび太
</option>
</select>
<textarea rows="2" cols="8">
スネ夫
</textarea>
<input type="text" value="しずちゃん" />
<label>
<input type="checkbox" name="n1" value="出木杉" />
出木杉
</label>
<label>
<input type="checkbox" name="n1" value="ドラミ" />
ドラミ
</label>
<input type="hidden" id="hdn1" value="怪物くん" />
<input type="submit" value="21エモン" />
</p>FireBugで確かめると‥‥
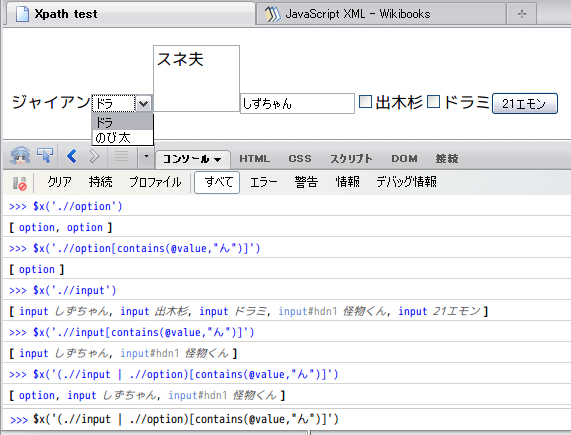
<option>タグはヒットしているようだが、中身の「ドラえもん」という文字列が表示されてないぞ。
まあ<option>タグの中身はtext()のほうで取得できているからデータを取り逃しているわけではない。
[合いの手] .//option は必要ない?
[話者] Firefox 3.6にはなくても問題ないな。
Safari/Chrome/Operaなどで必要なのかな?
[合いの手] @value って何?
[話者] リファレンスによると、
para[@type="warning"] はコンテキストノードの para という名前の子エレメントのうち、warning という値の type という名前のアトリビュートを持つものをすべて選択する。
つまり、input[@value] とは <input value="しずちゃん"> のような、<input>タグのvalue属性(アトリビュート)を取り出しているんだ。
[合いの手] ( | ) とか | はなんだろう?
[話者] これは正規表現と同じだと思うけど‥。 | は or のはず。
wikipedia:XML_Path_Languageに書いてある。
演算子 | は、述語の内部でも、述語の外部でも、ノード集合の和を求めるために使うことができる。
つまり .//input | .//option は、 .//input の結果と .//option の結果を足したものになるってこと。
[合いの手] なるほど‥‥。
これでソースコード全体がわかったことになるのかな
[話者] 文法的にわからないところを学んだので、データの流れを見直そう。
しかし Xpath ってみなさんどこで学ぶものなんだろう。テキストを扱う道具としての正規表現なみに、XMLを扱う道具としてのXpathは重要に思えるね。
[ http://d.hatena.ne.jp/itouhiro/20110107 に続きます]
")
標準講座 XQuery (Programmer’s SELECTION)
- 作者: StephenBuxton
- 出版社/メーカー: 翔泳社
- 発売日: 2008-03-12
- メディア: 大型本
おすすめ度の平均: エンタープライズITシステムのエンジニアに捧げられた本
エンタープライズITシステムのエンジニアに捧げられた本